Chapter 2 Data and variables
The truth is the science of nature has been already too long made only a work of the Brain and the Fancy. It is now high time that it should return to the plainness and soundness of Observations on material and obvious things.
Robert Hooke (1665)
The plural of anecdote is not data.
Roger Brinner
2.1 “Observations on material and obvious things”
As Hooke’s observation suggests, science cannot proceed on theory alone. The information we gather about a system stimulates questions and ideas about it and, in turn, can also allow us to test these ideas. In fact, the idea of measuring and counting things is so familiar that it is easy to start a project without giving much thought to something as mundane as the nature, quantity and resolution of the data we intend to collect. Nonetheless, the features of the data we collect determine the types of analyses that can be carried out and the confidence we can have in the conclusions drawn. In the end, no level of analytical sophistication will enable us to extract information that is not there to begin with.
So what is there to say about data? The first point to note is that there are many different sorts of data. We focus on simple kinds of data in this book, such as quantities (‘how much’) or classifications (‘what kind’), but not everything can be thought of in simple terms. Examples of more complex data types include spatial maps of species’ occurrence, the DNA sequences of individuals, and networks of feeding relationships among species (i.e. food webs) or gene activation (gene regulatory networks).
The data we collect in a study can be organised into one or more statistical variables. In its loosest sense, statisticians use the word ‘variable’ to mean any characteristic measured or experimentally controlled on different items or objects. People tend to think of variables as numeric quantities, such as cell size, but nothing stops us working with non-numeric variables, such as developmental stage.
Collectively, a set of related variables is referred to as a data set (or just ‘the data’). Confused? Consider a concrete example: the spatial maps of species’ occurrence mentioned above. A minimal data set might comprise two variables containing the x and y position of sample locations, a third variable denoting the presence/absence of a species, and one or more additional variables containing information about the environmental factors we measured.
Data and variables in R
Data sets are often stored in data frames when working with R. A data frame can be thought of as having rows and columns. Each column in a data frame has to be one of R’s many types of ‘vector’. Typically, these are simple things, like numeric or character vectors, but other kinds of vector can be used (e.g. dates and intervals of times). The data it contains are said to be tidy when each column of a data frame corresponds to a statistical variable, and each row corresponds to a single observation (a cell, a tissue sample, an animal, etc).
This simple connection between abstract statistical concepts and concrete objects in R is not a coincidence. Its structures and abstractions reflect the fact that R was designed first and foremost to analyse data.
The data are or the data is?
Strictly speaking, the word data is the plural of datum (a single piece of information), so we should say “the data are…” not “the data is…”. That said, the use of the word in the singular has become widespread, despite the objections of Grammar Nazis, and to be perfectly honest, either usage is fine these days. We lean towards plural usage with ‘data’, but both forms appear in this book…
2.2 Revision: Types of variable
When designing an experiment or carrying out some data analysis, it is vital to understand what sort of data we need, or have, as this affects what we can do with it. The variables in a data set are often classified as being either numeric or categorical:
- Numeric variables have values that describe a measurable quantity as a number, like ‘how many’ or ‘how much’.
- Categorical variables have values that describe a characteristic of an observation, like ‘what type’ or ‘which category’.
Numeric variables can be further characterised according to the type of scale they are measured on: interval vs. ratio scales. Categorical variables can be further characterised according to whether or not they have a natural order: nominal vs. ordinal variables.
This is probably the minimal classification scheme we need to learn if we want to analyse our data well. Let’s take a closer look at this scheme.
2.2.1 Nominal (categorical) variables
Nominal variables arise when observations are recorded as categories that have no natural ordering relative to one other. For example:
| Marital status | Sex | Colour morph |
| Single | Male | Red |
| Married | Female | Yellow |
| Widowed | Black | |
| Divorced |
Variables of this type are common in surveys where, for example, a record is made of the ‘type of thing’ (e.g. the species) observed.
2.2.2 Ordinal (categorical) data
Ordinal variables occur where observations can be assigned some meaningful order but the exact ‘distance’ between items is not fixed, or even known. For example, if we are studying the behaviour of an animal when it meets a conspecific, it may not be possible to obtain quantitative data about the interaction, but we might be able to score the behaviours in order of aggressiveness:
| Behaviour | Score |
| initiates attack | 3 |
| aggressive display | 2 |
| ignores | 1 |
| retreats | 0 |
Rank orderings are a type of ordinal data. For example, the order in which runners finish a race (1st, 2nd, 3rd, etc.) is a rank ordering. It doesn’t tell us whether it was a close finish or not but still conveys important information about the result.
In both situations, we can say something about the relationships between categories: in the first example, the larger the score, the more aggressive the response; in the second example, the greater the rank, the slower the runner. However, we can’t say that the gap between the first runner and the second was the same as between the second and third and we can’t say that a score of 2 is twice as aggressive as a score of 1.
How should you encode different categories in R?
We always have to define a coding scheme to represent the categories of nominal/ordinal variables in computerised form. It was once common to assign numbers to different categories (e.g. Female=1, Male=2). This method was sensible in the early days of computer-based analysis because it allowed data to be stored efficiently. This efficiency argument is no longer relevant. What’s more, there are good practical reasons to avoid coding categorical variables as numbers:
Numeric coding makes it harder to understand our raw data and interpret the output of a statistical analysis of those data. This is because we have to remember which number is associated with each category.
Numeric codes are arbitrary and should not be used as numbers in mathematical operations. In the above example, it is meaningless to say 2 [“male”] is twice the size of 1 [“female”].
R usually assumes that a variable containing numeric values is meant to be treated as a number. If we use numeric coding for a categorical variable, R will try to treat the offending variable as a number, leading to confusing errors.
The take home message: Always use words (e.g., ‘female’ vs. ‘male’), not numbers, to describe categories in R.
2.2.3 Ratio scale (numeric) variables
Ratio scale numeric variables have a true zero and a known and consistent mathematical relationship between any points on the measurement scale. For example, there is a temperature scale that has a true zero: the Kelvin scale. Zero K is absolute zero, where matter has no thermal energy whatsoever. Temperature measurements in degrees K are on a ratio scale, i.e. it does make sense to say that 60 K is twice as hot as 30 K. Ratio scale numeric variables are quite familiar, because the physical quantities that crop up in science are usually measured on a ratio scale: length, weight, and numbers of objects are good examples.
2.2.4 Interval scale (numeric) variables
Interval scale variables take values on a consistent numeric scale, but where that scale starts at an arbitrary point. Differences between values on an interval scale are meaningful, whereas ratios are not. The temperature on the Celsius scale is a good example of interval data. We can say that 60º C is hotter than 50º C, and we can say that the difference in temperature between 60º C and 70º C is the same as that between -20º C and -10º C. We cannot say that 60º C is twice as hot as 30º C. This is because temperature on the Celsius scale has an artificial zero value—the freezing point of water. The idea becomes obvious when we consider that temperature can equally well be measured on the Fahrenheit scale (where the freezing point of water is 32º F).
Continuous or discrete?
A common confusion with numeric data concerns whether the data are on continuous or discrete scales. Many biological ratio data are discrete (i.e. only certain discrete values are possible in the original data). Count data are an obvious example, e.g. the number of eggs found in a nest, the number of mutations in a cancer cell, or the number of heartbeats counted in a minute. These can only comprise whole numbers, ‘in between’ values are not possible.
However, the distinction between continuous and discrete data is often not clear cut – even ‘continuous’ variables such as weight are made discrete in reality by the fact that our measuring apparatus is of limited resolution (i.e. a balance may weigh to the nearest 0.01 g). So… keep in mind that the fact that data look (or really are) discrete does not mean they are necessarily truly discrete data.
2.2.5 Why does the distinction matter?
The measurement scale affects what we can do mathematically to a numeric variable. We can add and subtract interval scale variables, but we can not divide or multiply them and arrive a meaningful result. In contrast, we can add, subtract, multiply or divide ratio scale variables. Put another way, differences and distances are meaningful for both interval and ratio scales, but ratios are only meaningful for ratio variables (yes, the clue is in the name).
2.2.6 Which is best?
All types of data can be useful, but it is important to be aware that not all types of data can be used with all statistical models. This is one very good reason for why it is worth having a clear idea of the statistical tools we intend to use when designing a study.
In general, ratio variables are best suited to statistical analysis. However, biological systems often cannot be readily represented as ratio data, or the work involved in collecting good ratio data may be vastly greater than the resources allow, or the question we are interested in may not demand ratio data to achieve a perfectly satisfactory answer. It is this last question that should come first when thinking about a study. What sort of data do we need to answer the question we are interested in? Suppose it is clear at the outset that data on a rank scale will not be sufficiently detailed to enable us to answer the question. In that case, we must either develop a better way of collecting the data, or abandon that approach altogether. If we know the data we’re able to collect cannot address the question, we should do something else.
An obvious but important point: we can always convert measurements taken on a ratio scale to an interval scale, but we cannot do the reverse. Similarly, we can convert interval scale data to ordinal data, but we cannot do the reverse. That said, it’s good practice to avoid such conversions as they inevitably result in a loss of information.
2.3 Accuracy and precision
2.3.1 What do they mean?
The two terms accuracy and precision are used more or less synonymously in everyday speech, but they have quite distinct meanings in scientific investigation.
Accuracy – how close a measurement is to the true value of whatever it is you are trying to measure.
Precision – how repeatable a measure is, irrespective of whether it is close to the actual value.
Imagine we are measuring an insect’s weight on an old and poorly maintained balance, which measures to the nearest 0.1 g. In that case, we might weigh the same insect several times and each time get a different weight — the balance is not very precise, though some of the measurements might happen be quite close to the real weight. By contrast, we could be using a new electronic balance, weighing to the nearest 0.01g, but which has been incorrectly zeroed so that it is 0.2 g out from the true weight. Repeated weighing here might yield results that are identical but all incorrect — the balance is precise, but the results are inaccurate. The analogy often used is with shooting at a target:
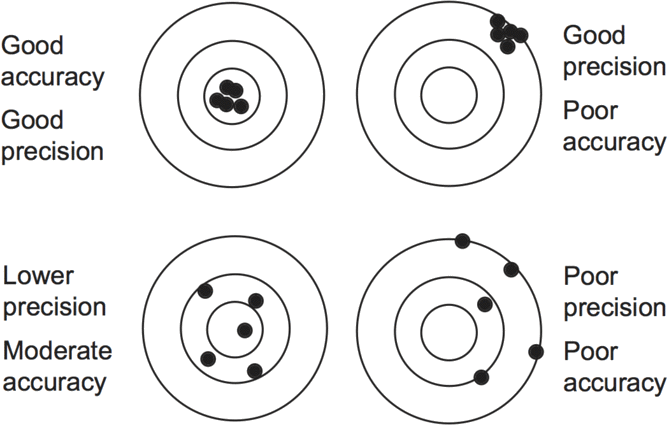
Figure 2.1: Accuracy and precision
It’s important to know how accurate and how precise our data are. The ideal is the situation in the top left target in the diagram. Still, high precision is not possible in many circumstances, and it is usually preferable to make measurements whose accuracy we can be reasonably confident (bottom left), than more precise measurements, whose accuracy may be suspect (top right). Taking an average of the values for the bottom left target would produce a value pretty close to the centre; taking an average for the top right target wouldn’t help the accuracy at all.
2.3.2 Implied precision – significant figures
It’s worth being aware that when we state results, we’re making implicit statements about the precision of the measurement. The number of significant figures we use suggests something about the precision of the result. A result quoted as 12.375 mm implies the measurement is more precise than one quoted as 12.4 mm. A value of 12.4 actually measured with the same precision as 12.735 should properly be written 12.400. When quoting results, look at the original data to decide how many significant figures to use—generally, the same number of significant figures will be appropriate.
These considerations do not apply in the same way when working with discrete data, e.g. precision of measurement is not an issue in recording the number of eggs in a nest. We use 4 not 4.0, but since 4 eggs implies 4.0 eggs it’s fine to quote average clutch size from several nests as 4.3 eggs. However, even with discrete data, if numbers are large then obviously precision is an issue again … a figure of 300 000 ants in a nest is likely to imply a precision of plus or minus 50 000. A figure of 320987 ants implies an improbably precise measurement.
2.3.3 How precise should measurements be?
The appropriate precision to use when making measurements is largely common sense. It will depend on practicality and the use to which we wish to put the data. It may not be possible to weigh an elephant to the nearest 0.001g, but if we want to know whether the elephant will cause a 10-tonne bridge to collapse, then the nearest tonne will be good enough. On the other hand, if we want to compare the mean sizes of male and female elephants, then the nearest 100 kg may be sufficient, but if we plan to monitor the progress of a pregnant female elephant, then the nearest 10 kg or less might be desirable.
As a rough guide aim, where possible, for a scale where the number of measurement steps is between 30 and 300 over the expected range of the data. For example, in a study of the variation in shell thickness of dogwhelks on a 300 m transect up a shore, it would be adequate to measure the position of each sampling point on the transect to the nearest metre, but shell thickness will almost certainly need to be measured to the nearest 0.1 mm.
2.3.4 Error, bias and prejudice
Error is present in almost all biological data, but not all error is equally problematic. Usually, the worst form of error is bias. Bias is a systematic lack of accuracy—i.e. the data are not just inaccurate—but all tend to deviate from the true measurements in the same direction (situations B and D in the ‘target’ analogy above). Thus there is an important distinction in statistics between the situation where the measurements differ from the true value at random and those where they differ systematically. Measurements lacking some precision, such as the situation illustrated in C, may still yield a reasonable estimate of the true value if the mean of a number of values is taken.
Avoiding bias in the collection of data is one of the most important skills in designing scientific investigations. Some forms of bias are obvious, others more subtle and hard to spot:
Non-random sampling. Many sampling techniques are selective and may result in biased information. For example, pitfall trapping of arthropods will favour collection of the very active species that encounter traps most frequently. Studying escape responses of an organism in the lab may be biased if the process of catching organisms to use in the study selected for those whose escape response is poorest.
Conditioning of biological material. Organisms kept under particular conditions for long periods may become acclimatised to those conditions. Similarly, if stocks are kept in a laboratory for many generations, their characteristics may change through natural selection. Such organisms may give a biased impression of the behaviour of the organism in natural conditions.
Interference by the process of investigation. Often the process of making a measurement itself distorts the characteristic being measured. For example, it may be hard to measure the level of adrenalin in the blood of a small mammal without affecting the adrenalin level in the process. Pitfall traps are often filled with a preservative, such as ethanol, but the ethanol attracts some species of insect that normally feed on decaying fruit and use the fermentation products as a cue to find resources.
Investigator bias. Measurements can be strongly influenced by conscious or unconscious prejudice on the part of the investigator. We rarely undertake studies without an initial idea of what we are expecting. For example, rounding up ‘in between’ values in the samples you are expecting to have large values and rounding down where a smaller value is expected, or having another ‘random’ throw of a quadrat when it doesn’t land in a ‘typical’ bit of habitat.
The ways in which biases, conscious and unconscious, can affect our investigations are many, often subtle, and sometimes serious. Sutherland (1994) gives an illuminating catalogue of how biases affect our perception of the world and the judgements we make about it. The message is that the results we get from an investigation must always be judged and interpreted with respect to the nature of the data used to derive them—if the data are suspect, the results will be suspect too.