Chapter 3 Learning from data
Statistics is the science of learning from data, and of measuring, controlling, and communicating uncertainty; and it thereby provides the navigation essential for controlling the course of scientific and societal advances.
The particular flavour of statistics covered in this book is called frequentist statistics. From a practical perspective, it is perfectly possible to apply frequentist tools by learning a few basic ‘rules’ about how they work. However, it is easier to apply a technique if we understand at least roughly how it works.
The goal of the next few chapters is to provide an overview of frequentist concepts without getting bogged down with the underpinning mathematics. We aim to arrive at a conceptual feel for the essential ideas. These can be difficult to understand at first. This is fine. We’ll return to them over and over again as we introduce different statistical models and tests.
We’re going to start by laying out a somewhat simplified overview of the steps involved in ‘doing frequentist statistics’ in this chapter. We’ll also introduce a few key definitions along the way. Later chapters will then drill into important concepts like sampling variation, standard errors, null hypotheses and p-values.
3.1 Populations
When a biologist talks about a population they mean a group of individuals of the same species that interact. What does a statistician mean when they talk about populations? The word has a very different meaning in statistics. Indeed, it is a much more abstract concept: a statistical population is any group of items or objects that share certain attributes or properties. This is best understood by example:
- The readers of this book could be viewed as a statistical population. This book is targeted at undergraduate students interested in biology. That group are primarily in their late teens and early 20s, and they tend to have similar educational backgrounds and career aspirations. As a consequence of these similarities, these students tend to be more similar to one another than they would be to a randomly chosen inhabitant of say, the US or Germany.
- The different areas of peatland in the UK can be thought of as a statistical population. There are many peatland sites in the UK, and although their precise ecology varies from one location to the next, they are also very similar in many respects. Peatland habitat is characterised by low-growing vegetation and acidic soils. If you visit two different peatland sites in the UK, they will seem quite similar compared to, for example, a neighbouring calcareous grassland.
- A population of plants or animals (as typically understood by biologists) can also be thought of as a statistical population. Indeed, this is often the kind of population ecologists are interested in studying. The individuals in a biological population share common behaviours and physiological characteristics, and much of biology is concerned with learning about these properties of organisms (e.g. development, physiology and behaviour).
We conceptualise populations as fixed and unknown entities within the framework of frequentist statistics. The goal of statistics is then to learn something about populations by analysing data collected from them. It is important to realise that the investigator defines ‘the population’, and ‘the something we want to learn about’ can be anything we know how to measure.
Consider the examples again:
- A social scientist might be interested in the political attitudes of undergraduates, so they choose to survey a group of students at university.
- A climate change scientist might measure the mass of carbon stored in peatland areas at sites across Scotland and northern England.
- A behavioural ecologist might want to understand how much time beavers spend foraging for food, so they might study a Scottish population.
So how does the process of learning about a population from data work?
3.2 Learning about populations
The three examples discussed above involve very different kinds of populations, questions and data. Nonetheless, there are fundamental commonalities in how those studies could be addressed. The process can be broken down into distinct steps:
Step 1: Refine your questions, hypotheses and predictions
We discussed this step in the scientific process chapter. The key point is that we should never begin collecting data until we’ve set out the relevant questions, hypotheses and predictions. This might seem obvious, but it is surprising how often people don’t get these things straight before diving into data collection. Collecting data without a clear scientific objective and rationale is guaranteed to waste a lot of time and energy.
Step 2: Decide which population(s) is (are) important
The second step is to decide which population(s) we should study. What constitutes ‘the population’ will be obvious in some kinds of study. In the three cases above, the corresponding populations we choose to study could be undergraduate students at a university, peatland habitats from across the UK, and beavers in Scotland.
It is fairly easy to define what we mean by ‘a population’ in those examples. However, the problem of deciding which population(s) to study can be more subtle than it first appears. What happens if we’re planning an experiment? Imagine that we want to test a prediction that nutrient addition reduces biodiversity in chalk grasslands. We might set up an experiment with two kinds of plots:
- manipulated plots where we add fertiliser, and
- control plots where we do nothing.
Comparing these in some way would allow us to assess the impact of adding nutrients. That’s easy enough to understand.
What can we say about the statistical populations in this example? First, there are two of them—control and manipulated communities—and they are completely defined by the experimental design. The nutrient addition plots don’t ‘exist’ until we do the experiment. That’s not hugely intuitive. What’s more, the weird mental contortion that a frequentist does is to imagine that the experimental plots are part of some larger, unobserved population of nutrient addition plots.
The important point is that statistical populations are something the investigator defines. They might be ‘real’, undergraduates at university, or they might be something that doesn’t exist in a meaningful way, like a population of not-yet-realised experimentally manipulated plots. In either case, we can use the same statistical techniques to learn something general about ‘the population(s)’.
Step 3: Decide which variables to study
The next step is to decide which attributes of the items that comprise our population(s) need to be measured. This comes down to deciding which variable(s) to measure. We discussed some of the considerations in the data and variables chapter. In the examples above, the appropriate variables would be things like a standardised measure of political attitude, the mass of stored carbon per unit area, or the body mass of individuals.
This step is often straightforward, though some effort may be required to pick among different options. There isn’t much ambiguity associated with a physical variable like body mass, but something like ‘political attitude’ needs careful thought. Can we quantify this by studying just one thing, like voting patterns? Probably not. Maybe we need to measure several things and aggregate those in some way.
Step 4: Decide which population parameters are relevant
Once we have decided which variables to study, we have to decide which population parameters are relevant. A population parameter is simply a numeric quantity that describes the variable(s) we want to learn about. A population parameter defines a property of that variable in the population—it’s not a property of the actual data.
A simple population parameter familiar to many people is the population mean. We often study means because they allow us to answer questions like, “how much, on average, of something is present?”. Quite a number of the statistical tests boil down to asking questions of population means. That doesn’t mean we can’t ask questions about other kinds of population parameters:
Statistical genetics aims to partition variability among individuals—we want to know how much phenotypic variation is due to genetic vs non-genetic sources. In this case, it is population variances we want to learn about.
Sometimes we want to understand how two or more aspects of the population are associated with one another. In this situation, something called a correlation coefficient might be the right parameter to focus on.
Once we have identified the population parameter we care about, we need a way to learn something about it. That takes us to the next step.
Step 5: Gather a representative sample
We would not need statistics if we could measure every member of a population. In that case, we would simply calculate the parameter of interest from an exhaustive sample. However, we always have limited time and money to invest in any problem in the real world. This means we usually have to work with a limited sample of the population. A sample is a subset of a population that has been selected to be representative. That word ‘representative’ is really important in this context. A representative sample is one that reflects the characteristics of the entire population.
It is really important to use sampling methods that lead to representative samples. Why? It’s very hard to infer anything useful about a population from a non-representative sample. For example, if we aim to understand the reproductive characteristics of our favourite study organism, but we only sample old-aged individuals, it will be impossible to generalise our findings when reproductive performance changes with age.
Collecting larger samples does not solve this kind of problem. For example, a sample that contains mostly old-age individuals doesn’t tell us much about younger age groups. People often assume that ‘more data = better data’ but that is not be true when the data are not representative of the population. Try to remember that in your own work.
Methods for obtaining useful samples and calculateing meaningful estimates are an important part of statistics. They fall under the banners of experimental design and sampling theory. These are large, technical topics that are well beyond the scope of this book. However, we will touch on a few of the more important aspects later.
Step 6: Estimate the population parameter
After acquiring a representative sample from a population we can calculate something called a point estimate of the population parameter. Remember, that parameter is ultimately unknown. A point estimate is a number that represents our ‘best guess’ at its true, unknown value. For example, if we are interested in the population mean, the obvious point estimate to use is the ‘the average’ we learn about at school.
There are many different kinds of point estimates we can calculate. What we choose to estimate depends on the question we’re answering. If we care about variability we might calculate one or more sample ‘variances’. Alternatively, we might calculate some kind of measure of an effect or change, like the difference between two sample means.
(By the way, people often say ‘estimate’ instead of ‘point estimate’, for the simple reason that saying or writing ‘point estimate’ all the time soon becomes tedious. We use both terms in this book.)
Step 7: Estimate uncertainty
A point estimate is useless on its own. Why? Because it is derived from a limited sample of the population. Even if we collect a huge representative sample, its composition won’t exactly match that of the population. This means any point estimate we derive from the sample will be imperfect in the sense that it won’t exactly match the true population value.
There is always some uncertainty associated with estimates population parameters. Our job as scientists is to to find a way to quantify that uncertainty. This part of the frequentist method is probably the hardest to understand so we’ll spend some time considering it in the sampling error chapter.
Step 8: Answer the question!
Once we have our point estimates and measures of uncertainty, we’re finally in the position to start answering questions.
Imagine that we want to answer a seemingly simple question, e.g. “Are there more than 200 tonnes of carbon per hectare stored in the peatland of the Peak District?” We might sample several sites, measure the stored carbon at each of these, and then calculate the mean of these measurements. What should we conclude if the sample mean is 210 t h-1? We can’t say much until we have a sense of how reliable that mean is likely to be. To answer our question, we have to assess whether the difference we observe (210 - 200 = 10) was just a fluke.
The tools we’ll learn about in this book are designed to answer many different kinds of scientific questions. Nonetheless, they all boil down to the same general question: is the pattern I see ‘real’, or is it instead likely to be a result of chance variation? To tackle this, we combine point estimates and measures of uncertainty in various ways. Statistical software like R will do the hard work for us, but we still just have to learn how to interpret the results it gives us.
3.3 A simple example
The best way to get a sense of how all this fits together is by working through an example (it is worth paying attention to this because we’ll use it again in later chapters). We’re only going to focus on steps 1-6 for the moment. The last two steps are sufficiently challenging that they need their own chapters.
Imagine we’re interested in a plant species that is phenotypically polymorphic. There are two different ‘morphs’: a purple morph and a green morph. We can depict this situation visually with a map showing where purple and green plants are located on a hypothetical landscape:
Figure 3.1: Stylised landscape showing a population of purple and green plants
These are idealised data generated using a simulation in R but proceed as though these they real.
Step 1: Refine your questions, hypotheses and predictions
Imagine we had also previously studied a different population of this species that exhibits the same polymorphism. We think the two populations were once connected but habitat loss has isolated them. Our previous studies with the old neighbouring population have shown:
A single gene with two alleles controls the colour polymorphism: a recessive mutant allele (‘P’) confers the purple colour and the dominant wild-type allele (‘G’) makes plants green. Genetic work has shown that the two alleles are present in a ratio of about 1:1 in the neighbouring population.
There seems to be no observable fitness difference between the two morphs in the neighbouring population. What’s more, about 25% of plants are purple. This suggests that the two alleles are in Hardy-Weinberg equilibrium. These two observations suggest that there is no selection operating on the polymorphism.
Things are different in the new study population. The purple morph seems to be about as common as the green morph, and preliminary research indicates purple plants seem to produce more seeds than green plants. Our hypothesis is, therefore, that purple plants have a fitness advantage in the new study population. Our prediction is that the frequency of the purple morph will be greater than 25% in the new study population, as selection is driving the ‘P’ allele to fixation.
(This isn’t the strongest test of our hypothesis, by the way. Really, we need to study allele and genotype frequencies, not just phenotypes. It is good enough for illustrative purposes.)
Step 2: Decide which population is important
This situation is made up, so consideration of the statistical population is a little artificial. In the real world, we would consider various factors, such as whether or not we can study the whole population or must restrict ourselves to one sub-population. Working at a large scale should produce a more general result, but it could also present a significant logistical challenge.
Step 3: Decide which variables to study
This step is easy. We could measure all kinds of different attributes of the plants—biomass, height, seed production, etc—but to study the polymorphism, we only need to collect information about the colour of different individuals. This means we are going to be working with a nominal variable that takes two values: ‘purple’ or ‘green’.
Step 4: Decide which population parameters are relevant
The prediction we want to test is about the purple morph frequency, or equivalently, the percentage, or proportion, of purple plants. Therefore, the relevant population parameter is the frequency of purple morphs in the wider population. We need to collect data that would allow us learn about this unknown quantity.
Step 5: Gather a representative sample
A representative sample in this situation is one in which every individual on the landscape has the same probability of being sampled. This is what people mean when they refer to a ‘random sample’. Gathering a random sample of organisms from across a landscape is surprisingly hard to do. Fortunately, it is very easy to do in a simulation. Let’s seen what happens if we sample 20 plants at random…
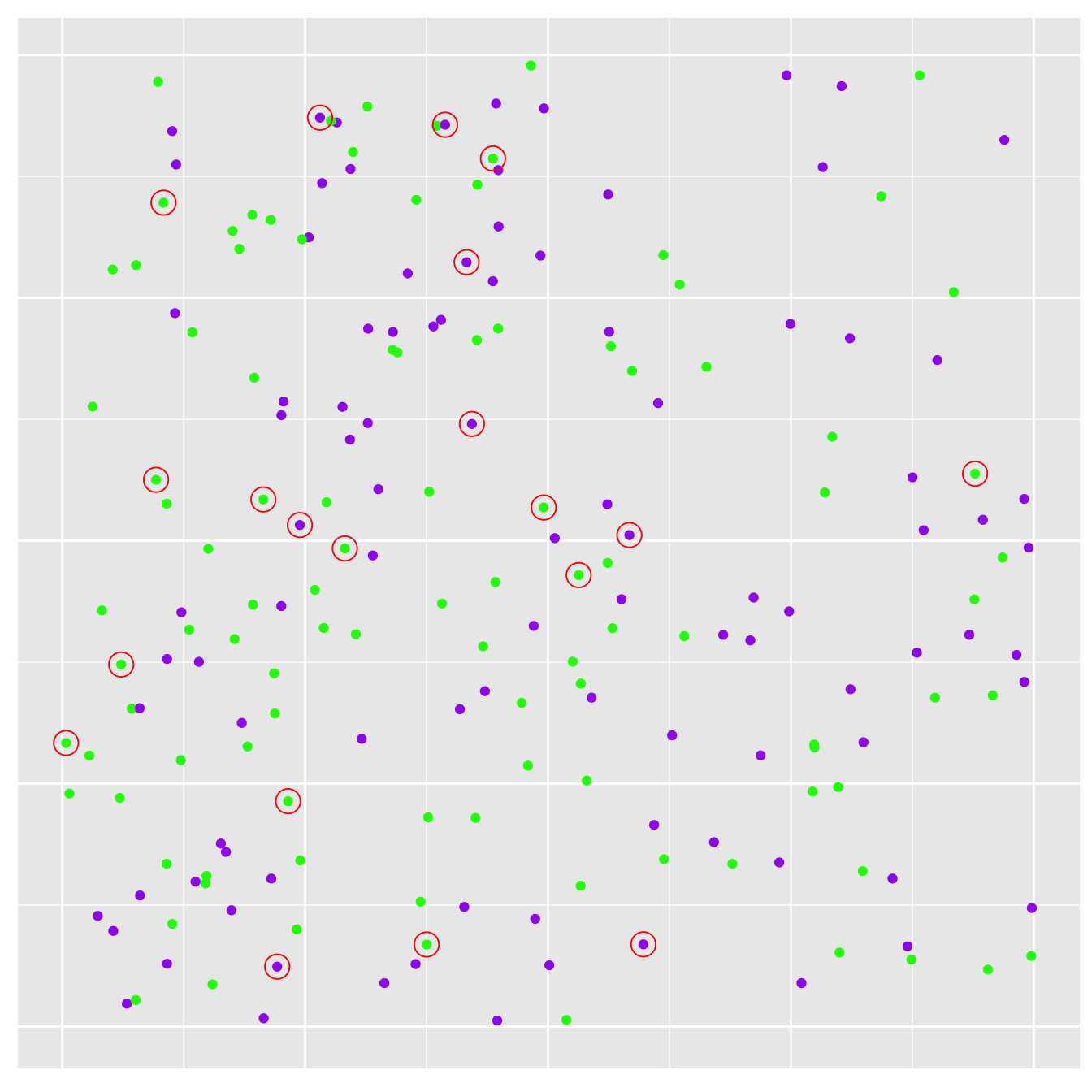
Figure 3.2: Sampling plants. Sampled plants are circled in red
The new plot shows the original population of plants, only this time we’ve circled the sampled individuals in red. We would only ‘see’ this sample of plants in the real world.
Step 6: Estimate the population parameter
Estimating a frequency from a sample is simple enough though we can express frequencies in different ways. We’ll use a percentage. We found 12 green plants and 8 purple plants in our sample, which means our point estimate of the purple morph frequency is 40%. This is certainly greater than 25%—the value observed in the original population—but it isn’t that far off when you consider this is from a small sample.
3.4 Now what?
Maybe the purple plants aren’t at a selective advantage after all? Or perhaps they are? We’ll need to develop a rigorous statistical test of some kind to evaluate our prediction. Before we can do this we need to delve into a few more concepts. The first, sampling error, is needed describe the uncertainty in the purple morph frequency estimate (step 7). We’ll look at this topic in the next chapter. After that, we’ll be in the position to answer our question about differences among the two populations (step 8).